
1. The economics of Intelligence on Tap
From search engine to intelligence utility
In 1999, Larry Page and Sergey Brin had a problem. Google was processing 3.5 million searches a day on hardware that could barely keep up. The company was burning through servers, running out of money, and facing a fundamental question that had nothing to do with whether search was valuable. Everybody knew search was valuable. The question was whether anybody could afford to deliver it.
Their answer was to reinvent the stack. Instead of buying expensive enterprise servers from Sun or IBM, they built custom racks from commodity PCs - cheap, failure-prone machines held together by software that made the whole cluster reliable. The result was roughly a 20x cost advantage over anyone running traditional infrastructure. That cost advantage didn’t just make Google profitable. It made ad-supported search, a product given away for free to billions of users, one of the most lucrative business models in the history of technology.
Twenty-five years later, we are watching the same movie play out with artificial intelligence. The technology works. Demand is exploding. And the unit economics don’t yet support the business model that the market requires. The question, once again, is not whether AI is real. The question is whether anyone can afford to deliver it at the scale the world wants to consume it.
History says they can. History also says the path from “this works” to “this is a utility” is an engineering problem, not a science problem, and the companies that solve it will define the next era of technology.
The 1,000x cost collapse
The single most important number in AI economics is this: the cost of generating a token of AI output has fallen roughly 1,000x in three years.
When OpenAI first made GPT-3 available via API in late 2021, the cost was approximately $60 per million tokens. By late 2024, equivalent-capability inference through models like GPT-3.5 Turbo had dropped to roughly $0.07 per million tokens. That’s a 1,000-fold reduction, according to data from Epoch AI and a16z’s “LLMflation” research.
For context, Moore’s Law delivered a 2x improvement in compute price-performance roughly every two years. LLM inference costs are declining at approximately 10x per year, about seven times faster than Moore’s Law at its peak. No comparable technology has ever dropped in cost this rapidly.
The decline has been relentless across every major model provider:

A clear pattern has emerged: roughly 18 months after a frontier model launches, equivalent capability is available at commodity prices. GPT-4’s performance level went from $36 per million tokens to under $1 through open-source alternatives in about 18 months. What was state-of-the-art last year is a commodity today.
The Google precedent
Google’s financial history provides a precise template for understanding where AI goes next. The parallels are not metaphorical. They are structural.
When Google went public in 2004, it generated $3.2 billion in revenue from roughly 73 billion searches per year. It spent $1.5 billion on traffic acquisition costs, the payments to partners like AOL, Firefox, and later Apple that directed users to Google’s search engine. TAC consumed 45.7% of revenue.
Over the next twenty years, a remarkable thing happened. Revenue grew 110x, from $3.2 billion to $350 billion. But traffic acquisition costs grew only 38x, from $1.5 billion to $55.6 billion. As a share of revenue, TAC dropped from 45.7% to 15.9%.

Meanwhile, search volume grew from approximately 73 billion queries per year in 2004 to an estimated 6 trillion in 2025, an 81x increase, but revenue grew 110x. Google didn’t just process more queries; it extracted more value from each one, because scale economics drove down the marginal cost of serving a query while advertising monetization improved.
The underlying dynamic was straightforward. Google’s cost per query fell from roughly 0.5–1.0 cents at IPO to 0.03–0.1 cents by 2022, a 10–30x decline, while revenue per query rose from about 0.5 cents to 1.6 cents. Costs went down, revenue per unit went up, volume exploded. That is the playbook.
Google didn’t make search cheaper. Google reinvented the stack so search could exist at all.
Where AI economics stand today
AI’s unit economics in 2026 look almost exactly like Google’s in 2001: the technology works, users are flooding in, and the companies providing it are hemorrhaging money.
OpenAI generated $3.7 billion in revenue in 2024 but lost roughly $5 billion. Its compute spend alone, $5 billion between training, inference, and research, exceeded total revenue. Sam Altman publicly confirmed that OpenAI loses money on ChatGPT Pro, its $200-per-month power-user subscription. The daily cost of running ChatGPT is estimated at $700,000 to $3 million, depending on the source.
The structural gap between AI inference and Google Search is real, but it’s narrowing:
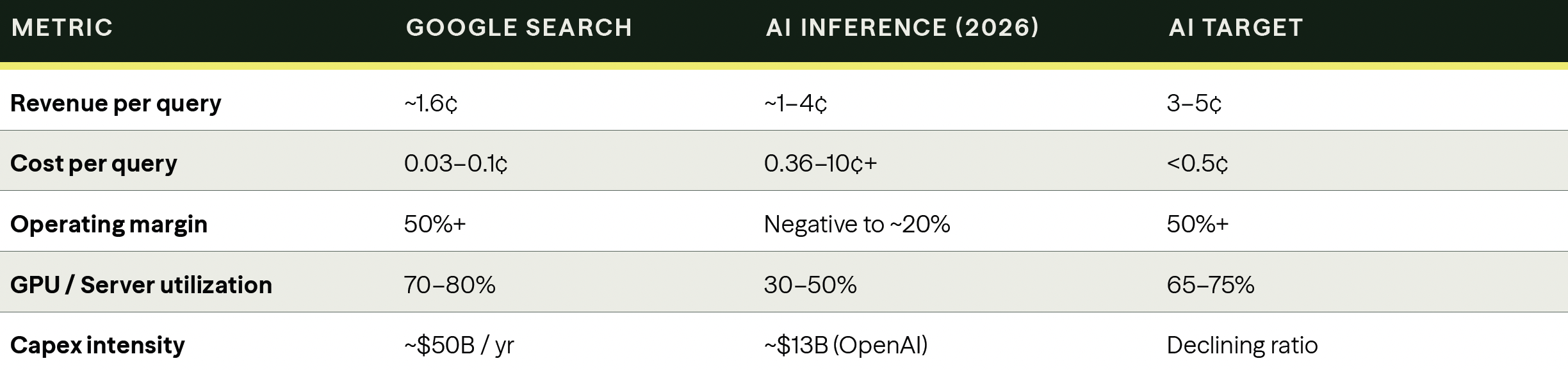
Three structural factors explain this gap. First, AI generates rather than retrieves. A search query triggers a lookup in a pre-built index; an AI query requires a forward pass through a neural network with billions of parameters, consuming orders of magnitude more compute. Second, large models require dedicated memory allocation even when idle, which crushes utilization rates. Third, subscription pricing creates heavy-tail usage patterns where power users consume 100x the compute of average users, making per-user economics wildly uneven.
But each of these is an engineering operational constraint, not a fundamental limitation. And we can already see them being solved.
The demand explosion
While costs are collapsing, demand is growing at rates that would have seemed absurd two years ago.
ChatGPT now handles over 1 billion queries per day, with 800–900 million weekly active users. OpenAI’s API processes 2.2 billion daily requests. OpenRouter, a multi-provider inference platform, went from processing 10 trillion tokens per year to over 100 trillion tokens per year between 2024 and 2025, a 10x increase in twelve months. The platform now handles more than 1 trillion tokens per day.
ChatGPT message volume grew 8x year-over-year, per OpenAI’s 2025 State of Enterprise AI report. That’s not just more users. It’s more intensive usage per user. Average prompt length has quadrupled, from roughly 1,500 tokens per API request in early 2024 to 6,000 tokens by late 2025, as developers send more complex instructions and larger context windows become standard.
The application layer tells the same story. GitHub Copilot grew from 5 million to 20 million users in a year, with 90% of Fortune 100 companies now using it. Cursor became the fastest-growing SaaS product in history, growing from $100 million to $1.2 billion in annual recurring revenue in a single year. Reasoning models, which didn’t exist before December 2024, now account for more than 50% of all token consumption on multi-provider platforms.
Jevons paradox
Despite a 1,000x reduction in the cost per token, organizations saw their AI spending increase by 320% year-over-year, according to OpenAI’s enterprise data. They didn’t pocket the savings. They consumed vastly more. After DeepSeek demonstrated dramatically cheaper inference, Satya Nadella publicly invoked the Jevons Paradox: “As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can’t get enough of.”
This pattern is the defining feature of every technology that becomes a utility:

Google’s own history makes this concrete. Between 2004 and 2024, the cost per search query fell approximately 30x. But search volume grew 81x, and revenue grew 110x. The volume curve didn’t just match the price curve. It overwhelmed it. Revenue grew faster than either cost fell or volume rose, because cheaper delivery made the product accessible to use cases that were previously uneconomical.
The scissors: Training vs. inference
Underneath the headline numbers, a structural divergence is reshaping AI’s economics in a way that directly parallels Google’s infrastructure evolution.
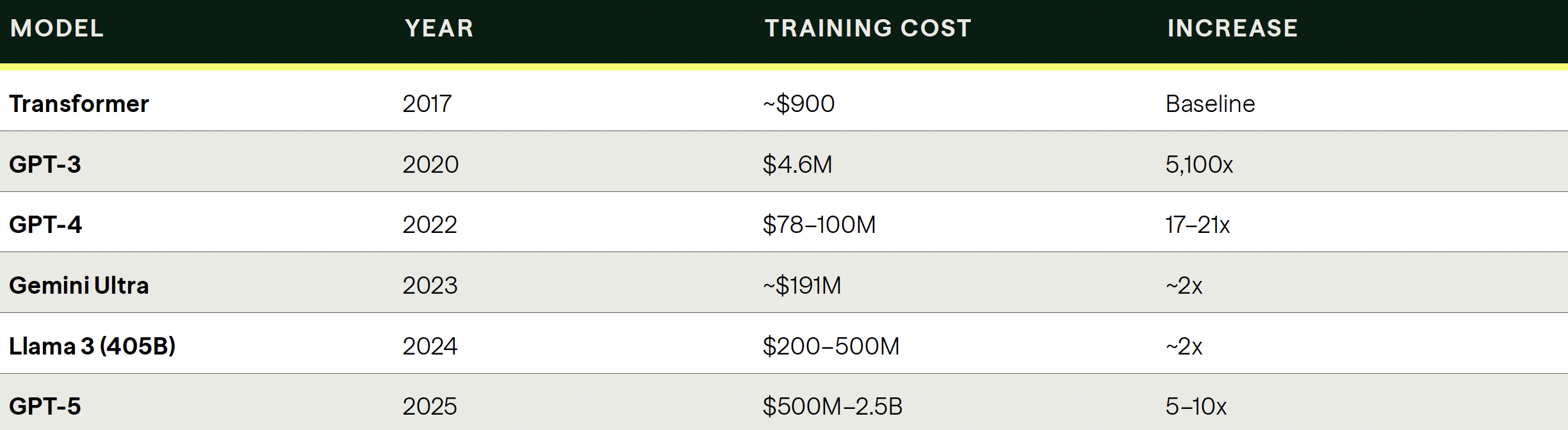
Training costs, the upfront investment to build a model, are accelerating exponentially. The original Transformer architecture cost approximately $900 to train in 2017. GPT-3 cost $4.6 million in 2020. GPT-4 cost $78–100 million. Estimates for GPT-5 range from $500 million to $2.5 billion. Epoch AI data shows training costs growing at 3.5x per year. Anthropic CEO Dario Amodei and team pointed this out while they were at OpenAI.
Meanwhile, inference costs, the marginal cost of serving each query, are collapsing at 10x per year. This is the scissors dynamic: the fixed cost of creating intelligence rises while the variable cost of delivering it falls. This creates a business model that looks a lot like Google’s: enormous upfront capital expenditure amortized across billions of transactions at trivial marginal cost.
The hardware cost curve reinforces this trajectory. GPU cloud pricing for H100s has fallen from roughly $4 per hour in early 2024 to $1.38 per hour in March 2026, a 65% decline, driven by overcapacity as NVIDIA’s Blackwell generation ramps production. B200 GPUs, unavailable a year ago, now start at $2.40 per hour. Each GPU generation delivers approximately 2x the price-performance of the prior generation, and the cloud market’s competitive dynamics accelerate the pass-through to end users.
Late 2025 marked a structural milestone: for the first time, inference surpassed training in data center revenue. By 2030, analysts project inference will account for 65–70% of all AI compute spending, up from roughly 25% in 2023. AI is transitioning from the “build” phase to the “serve” phase, exactly the trajectory that turned Google’s infrastructure investment into a cash-generating utility.
Where the value accrues
If the Google parallel holds, then the question for investors is not whether AI becomes an affordable utility. It’s who captures the value as it does.
Google’s lesson is that the company that solves the infrastructure problem captures the economics. Google didn’t win search because it had the best algorithm (though it did). It won because it rebuilt the server stack so completely that no competitor could match its unit economics. AltaVista had search. Yahoo had search. They didn’t have the infrastructure economics to sustain it at the scale the internet demanded.
Today’s AI landscape presents the same opportunity. The inference market is projected to grow from $106 billion in 2025 to $255 billion by 2030, a 17–19% CAGR. But the companies that will capture that value disproportionately are the ones solving the hardest engineering constraints: utilization efficiency, model serving optimization, and hardware-software co-design that drives marginal cost below the revenue line.
The signals are already visible. Custom silicon programs at Google (TPUs), Amazon (Trainium), and Microsoft (Maia) echo Google’s original commodity-server strategy. Open-source models like Meta’s Llama family are commoditizing the model layer, shifting value to the infrastructure and application layers, just as the proliferation of web content shifted value from content creation to search and distribution. Inference optimization startups are pursuing the same kind of fundamental cost reduction that Google’s early server team achieved.
The AI industry’s $5–9 trillion infrastructure buildout through 2030 is not a bubble. It is the same kind of capital cycle that built the electric grid, the telephone network, and the cloud. The returns will not go to everyone who spends the capital. They will go to the companies that spend it most efficiently: the ones who reinvent the stack. AI is going through a similar process to those historical examples, albeit in a way that it is still not entirely clear where the value capture ultimately lands.
Sources and data notes
Token costs: OpenAI API pricing; blended = 80% input / 20% output per Andrew Ng methodology.
Google financial history: Alphabet 10-K filings; 2025 estimated from quarterly reports.
Structural gap between AI inference and Google Search: SemiAnalysis, Alphabet 10-K, industry estimates.
Technology as a utility costs: EIA, Cisco, Alphabet 10-K, Epoch AI, Markets and Markets.
Training costs: LambdaLabs, Stanford AI Index 2024, Epoch AI, TechRadar.

Download the full report
The economics, architecture, and future of AI, and what must change for ubiquitous, on-demand intelligence to become a sustainable, long-term reality.



