
6. From concentration to diffusion
The value inversion
In 1879, the Erie Railroad went bankrupt for the second time. The track was laid, the freight was moving, and the capital that built it was gone. A few hundred miles away, John D. Rockefeller did not own a mile of track. He used the rails, negotiated the rates, and built a national distribution business on infrastructure other people had paid for. By 1900, his fortune was the largest in the country and the Erie was on its third bankruptcy.
This is the pattern at the end of every infrastructure phase. The builders create the platform. The operators capture the value.
Almost everything people call 'AI adoption' today is concentrated in two places.
More than 50% of all token consumption on multi-provider platforms flows to software programming tasks. Content generation — drafting, summarizing, editing — accounts for most of the remainder. When industry surveys report that 92% of Fortune 500 companies are using AI, they are reporting on access, not depth. They are reporting on beachheads, not diffusion.
The concentration runs deeper than application categories. On the supply side, a small number of chip suppliers extract the highest margins in the stack. A handful of foundation labs control frontier model development. A concentrated set of hyperscaler customers account for the majority of AI infrastructure spending. By almost every metric — revenue, compute consumption, development investment — AI value capture in 2026 sits at the narrow end of a pyramid that is supposed to widen into a utility available to everyone.
This is normal. Every technology in its infrastructure-build phase looks like this. The commercial internet in 1997 was used primarily by people with enough technical sophistication to navigate it, for a narrow set of applications that worked on early dial-up connections. Semiconductors in 1980 were deployed by defense contractors, mainframe manufacturers, and a small number of technology companies. Electricity in 1900 powered factories and wealthy urban households, not farms, hospitals, or rural small businesses. Less than 10% of organizations today have successfully scaled AI agents in any business function, a figure that would look familiar to anyone who tracked enterprise software adoption in 1996 or 1997.
The concentration is a starting condition, not a destination. The question for investors is not whether diffusion happens; history is unambiguous that it does. The harder question, and the one this piece is about, is the value inversion that follows. The question is which industries cross the adoption threshold next, what those thresholds actually require, and where the value accrues when diffusion is complete.
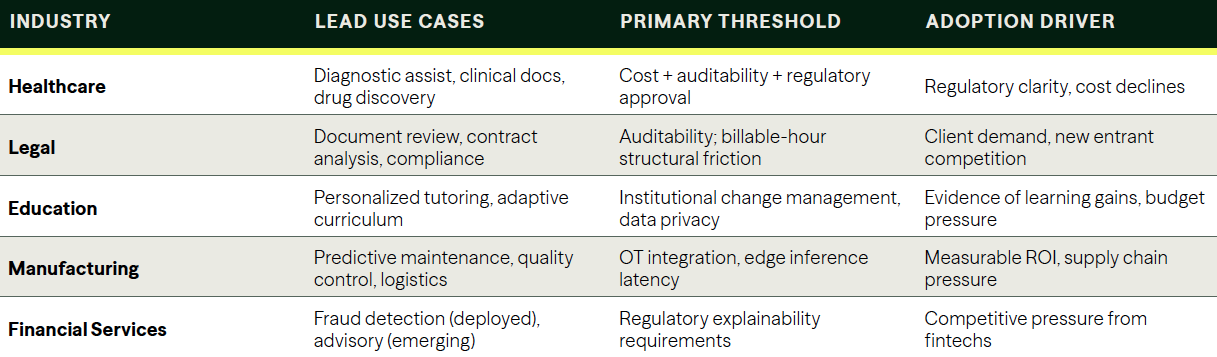
The five thresholds
Each of the industries on the cusp of significant AI adoption has a specific set of requirements that current AI does not yet fully meet. The threshold analysis matters more than the technology timeline: these sectors will not adopt in the order that AI becomes capable, but in the order that cost, reliability, and regulatory conditions align simultaneously.
Healthcare is the most frequently cited next wave and the most structurally complex. Diagnostic assistance, clinical documentation, and drug discovery acceleration represent enormous addressable value. The FDA approved more than 500 AI-enabled medical devices through 2023, and diagnostic AI has demonstrated radiologist-level accuracy in controlled imaging studies. The threshold requirements are strict on three dimensions at once: inference costs must fall further to make per-patient economics viable at primary care scale, reliability standards require consistent performance rather than probabilistic output, and regulatory frameworks for AI-assisted clinical decisions are still being written. The opportunity is large, and the timeline is real. The adoption path runs through procurement committees, liability frameworks, and compliance infrastructure, not just engineering.
Legal services present a structurally different version of the same problem. Document review, contract analysis, and regulatory compliance are tasks where AI already demonstrates measurable value on benchmarks. The adoption constraint is auditability: a model that confidently cites a case that does not exist is not an assistive tool; it is a malpractice risk. There is also a structural friction specific to the legal industry that most technology forecasts underweight: the billable-hour model means that efficiency gains from AI compress revenue for the firms adopting it. Adoption will be driven by clients demanding lower costs and by new entrants structuring their practices around AI from the start, not by incumbent firms voluntarily reducing their own billing capacity.
Education has the most technically straightforward case and the most institutionally complicated one. Personalized tutoring at scale — a capable, responsive tutor available to every student, not only those whose families can afford one — is achievable with current AI capability. Early deployments have demonstrated real learning gains in controlled settings. The threshold requirements here are not technical: they are data privacy frameworks for minors, procurement processes in systems that move slowly, and the cultural question of how AI tools interact with teaching as a profession. The institutional change management is the constraint, not the technology.
Manufacturing and logistics may be the sector where adoption has already crossed the threshold in a way that has not generated proportional press coverage. Predictive maintenance, supply chain optimization, and quality control are use cases where integration with existing operational technology is challenging but tractable, the value per interaction is measurable and immediate, and the regulatory exposure is low compared to healthcare or legal. The next layer is real-time inference at the factory edge, which requires latency and cost reductions already underway. This is less a question of whether AI enters manufacturing than how quickly it reaches the long tail of mid-market manufacturers who cannot afford bespoke implementations.
Financial services sit across the threshold in some applications and short of it in others. Fraud detection and risk modeling are deployed at scale in large institutions today — these are not future applications. The next layer is customer advisory and credit analysis, where regulatory frameworks require explainability that current models provide inconsistently. Regulation B's adverse action notice requirements in consumer credit and fiduciary standards in investment advice create compliance floors that AI systems must clear before deployment. As in legal, adoption of the harder use cases will be driven more by competitive pressure from new entrants than by incumbent institutions voluntarily disrupting their own processes.
Three patterns, one conclusion
History offers three independent templates for how technology value migrates during and after a diffusion phase. They converge on the same answer.
The railroad parallel is the most instructive for investors because it is the most counterintuitive. Between 1865 and 1890, the United States built approximately 150,000 miles of railroad track in the largest infrastructure investment in American history to that point, and also one of the greatest capital destruction events in American financial history. Most of the major railroad companies went through bankruptcy at least once. The Erie Railroad went bankrupt twice. Capital was consumed at a rate that shocked even the investors who had funded it. And yet the railroads created something more valuable than anything the railroad operators captured: they created the conditions for an entirely different tier of wealth. Standard Oil used railroad logistics to build national distribution infrastructure no competitor could replicate. Sears used the railroad network to reach rural customers no retailer had previously been able to serve. Carnegie Steel used railroad demand and railroad cost structures to achieve dominance in an industry that became global. The infrastructure built the platform. It did not capture the value that ran on top of it.
The semiconductor transition offers a second template with a shorter and more precisely documented timeline. The shift from bipolar to CMOS transistors reshaped the industry over approximately fifteen years, from the mid-1980s to 2000. The companies that led the bipolar era — Fairchild, National Semiconductor — were not the ones that won CMOS. Intel built the microprocessor. TSMC built the foundry model. But the largest fortunes of the personal computing era were built not by Intel or TSMC, but by the companies that used cheap CMOS compute to build software franchises that have proven more durable than any chip architecture: Microsoft, Oracle, Cisco. Later, Google and Apple. The chip transition was the prerequisite. The software layer was the prize.
The internet adoption curve provides the third template, and its most important lesson is about the relationship between technology availability and value capture. E-commerce was commercially available in 1994. It took fifteen years to reach 15% of U.S. retail. Enterprise SaaS companies had working products by 1999. It took a decade for SaaS to materially displace on-premises software. At each stage, the first-wave winners of the transition were not the same as the second-wave winners. Portals and early search engines dominated the first phase of internet adoption. Google, Amazon, Apple, and Meta defined the second phase. The companies positioned to capture durable value in the second wave were either not yet dominant or did not yet exist at the start of the adoption curve. The investment implication is direct: the timing of portfolio weight shifts matters as much as the direction of the technology.
The value inversion
Three historical patterns, three independent lines of evidence, one conclusion: infrastructure buildouts enable application-layer dominance. The cost stack, the architecture choice, the routing layer, and the inference-flexibility thesis from the prior pieces in this series all describe the mechanics of how the inversion happens. The companies that build the pipes rarely own the water.
The companies that build the pipes rarely own the water. The question for every AI investor: are you funding pipes or water
The AI transition to commodity economics is not yet complete. Based on the trajectory of inference cost declines and the competitive dynamics among foundation labs, open-weight models, and custom silicon programs, the transition to commodity-level pricing is likely to be completed by 2027-2028. That timeline is consistent with Google's own infrastructure reinvention, which required approximately five to seven years from the late 1990s to its full expression in 2006.
When that transition completes, the value stack inverts. Chips, models, and inference compute become competitive inputs rather than sources of monopoly margin. The prize shifts to the application layer: the companies that used cheap, reliable, widely available AI to build durable positions in industries that are only beginning to adopt it. The companies that will look, from 2030, the way Standard Oil looked from 1900, or Microsoft looked from 2000, or Google looked from 2010.
This is not an argument against infrastructure investment. The railroads were necessary. The CMOS fabs were necessary. The hyperscaler GPU clusters are necessary. None of the application-layer value in any of these historical cycles would have materialized without the infrastructure buildout that preceded it. But the investment question is not only whether to fund AI infrastructure, it is whether the portfolio is positioned for the value inversion that follows.
The concentration visible in AI today — in chips, in model development, in paying customers — is the signature of an infrastructure phase. It is the railroad era, the bipolar transistor era, the dial-up internet era. It is the phase that creates the platform. The diffusion phase that follows is the one that creates the lasting fortunes, in industries and applications that are currently underestimated precisely because they have not yet crossed their adoption thresholds.
Intelligence on Tap will be a reality when a doctor in a rural clinic, a small business owner without an IT department, and a student in an underfunded school district all have access to the same quality of intelligence that a Fortune 500 company deploys today.
The technology to deliver that is already in development. The economics are moving in the right direction at an unprecedented pace. The value question is who builds what runs on top of it.
Every technology cycle asks the same question. The answer, across railroads and semiconductors and the internet, has been consistent. The question for every investor in this space is the one that mattered in 1880, and in 1990, and in 2000: are you funding the pipes, or the water?
Sources and data notes
AI usage concentration: a16z/OpenRouter, 'State of AI 2025' (100 Trillion Token Study); OpenAI, 'State of Enterprise AI 2025.'
Enterprise AI scaling: Bain, 'AI's Trillion-Dollar Opportunity 2024' (less than 10% of organizations have scaled AI agents in any function).
Healthcare AI: FDA AI-enabled medical device approvals database; Stanford HAI AI Index 2025.
Railroad history: Chandler, 'The Visible Hand: The Managerial Revolution in American Business'; U.S. Census Bureau railroad mileage data 1865-1890.
Semiconductor transition: Flamm, 'Mismanaged Trade? Strategic Policy and the Semiconductor Industry'; Intel and TSMC historical filings.
Internet adoption curves: U.S. Census Bureau e-commerce retail data; Gartner enterprise SaaS adoption surveys.
AI commodity economics timeline: Epoch AI inference cost trend data; Google Alphabet 10-K historical filings.

Download the full report
The economics, architecture, and future of AI, and what must change for ubiquitous, on-demand intelligence to become a sustainable, long-term reality.



