5. Beyond transformers
The search for new intelligence
In 1985, the dominant logic transistor technology was bipolar. Bipolar transistors were fast, proven, and backed by decades of engineering investment. The companies that had built the deepest bipolar expertise — Fairchild, National Semiconductor, and analog specialists across the industry — were not making a foolish bet. They were betting on the best available technology, supported by manufacturing scale and a concentration of talent that had no peers.
They were also betting on the wrong architecture. CMOS transistors had existed for years but were initially slower and less capable than bipolar. What they had was a different set of economic properties: a fraction of the power consumption, dramatically better scaling with each manufacturing generation, and a cost structure that let them proliferate into applications bipolar could not reach. Within a decade, CMOS dominated. The companies that had led the bipolar era were not the ones that won the CMOS era.
The AI industry could be at an analogous moment. Transformers, the architecture underlying every major language model deployed at scale today, are genuinely extraordinary. They may also not be the final form of intelligence. The open question, one that carries significant capital implications, is not whether alternatives will emerge, but which ones, when, and what that means for the infrastructure currently being built to serve a transformer-centric world.
What transformers do brilliantly
It would be a mistake to underestimate the transformer architecture in the process of arguing it will eventually be supplanted. The core mechanism — attention, which allows the model to weigh the relevance of every token in a sequence against every other — has proven remarkably general. Language understanding, code generation, image recognition, protein structure prediction, mathematical reasoning: transformers have produced state-of-the-art results across domains that researchers did not initially expect the architecture to handle.
The scaling properties have been equally extraordinary. As compute and data increase, transformer performance improves in ways that have been largely predictable. This predictability is what allowed OpenAI, Anthropic, and Google to justify spending hundreds of millions of dollars on individual training runs: the returns are estimable. The architecture has been refined by thousands of researchers over nearly a decade, with optimizations at every layer of the stack.
Transformers earned their dominance. The question is whether dominance is permanent.
The cracks
The transformer's central limitation is also the source of its strength. Attention compares every token against every other token in a sequence, which means compute requirements scale quadratically with sequence length. Double the context window and attention compute quadruples. This is manageable at 4,000 tokens. It becomes expensive at 100,000 tokens and genuinely prohibitive at million-token contexts, which is exactly the kind of long-horizon reasoning that the most valuable AI applications will eventually require.
A second limitation, less discussed but equally consequential, is that transformers are statistical pattern matchers. They predict the most probable next token based on patterns in training data. For language tasks, this is extraordinarily powerful — human-generated text encodes vast amounts of implicit structure that the model learns to replicate. For tasks requiring verifiable correctness, such as mathematical proof, legal analysis, clinical diagnosis, and financial modeling, 'statistically plausible' and 'provably right' are different things. Transformers excel at the former. They struggle with the latter.
A third limitation matters most for embodied applications. Transformers learn the structure of language by training on text. They do not learn the structure of causality by acting in environments. For autonomous driving, robotics, simulation, and any domain where a model must predict what the world will do in response to what an agent does, the transformer is not the right primitive. The relevant primitive is action-conditioned, not token-conditioned.
These are not product flaws that can be patched in the next model release. They are architectural properties. And they are driving serious research and investment in alternative approaches that are already past the theoretical stage.
The alternatives taking shape
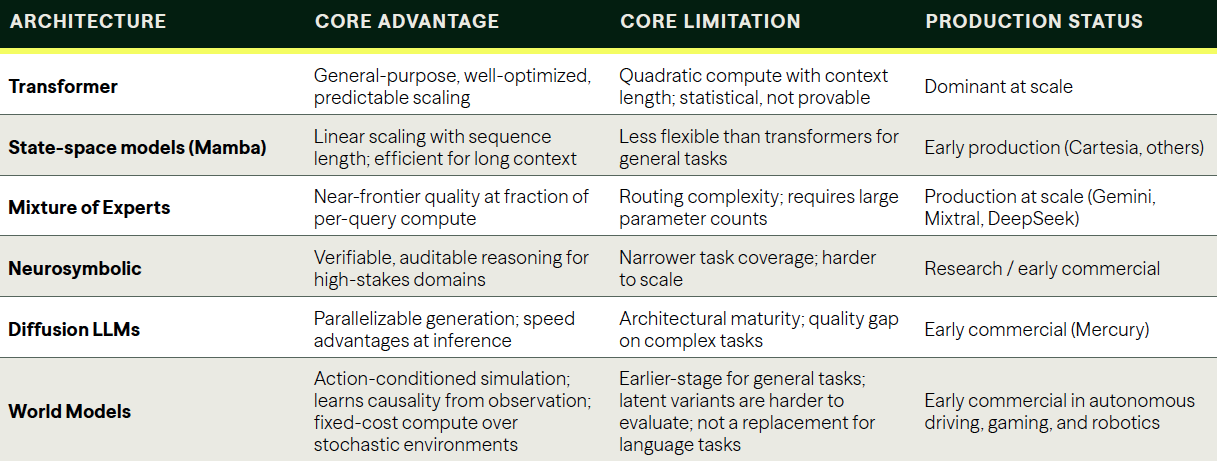
Five architectural directions have moved from research papers into production deployments.
State-space models: Where transformers process sequences by comparing every token to every other, state-space models process sequences more like a signal filter: they maintain a compressed memory state that updates as new tokens arrive, rather than reprocessing the full sequence for each new input. The practical result is linear rather than quadratic scaling with sequence length, a fundamental efficiency advantage for long-context tasks. The Mamba architecture, developed by researchers at Carnegie Mellon and Princeton, demonstrated competitive performance against transformers at a fraction of the compute for long sequences. Cartesia, one of several startups commercializing state-space approaches, is already deploying the technology in production speech and language applications.
Mixture of experts: Rather than activating an entire model for every query, Mixture of Experts architectures maintain many specialized sub-networks and route each query to only the relevant subset. A model might contain a trillion parameters total but activate only 20 billion for any given query, delivering near-frontier quality at dramatically lower per-query compute. This is not a future direction — it is in production at scale today. Google's Gemini and Mistral's Mixtral are both MoE architectures. DeepSeek's models, which drew significant market attention in early 2025, are also MoE-based, and the cost advantages they demonstrated contributed directly to investor reassessment of AI infrastructure economics.
Neurosymbolic systems: Transformers understand language; they struggle to prove things. Neurosymbolic architectures combine neural pattern recognition with structured logical reasoning, producing systems that can both understand a problem and verify a solution against formal rules. For domains where 'statistically plausible' is insufficient, such as legal analysis, clinical decision support, scientific research, and financial modeling, neurosymbolic approaches offer something pure transformers cannot: auditable reasoning. DeepMind's AlphaProof, which solved International Mathematical Olympiad problems by combining language model reasoning with formal proof verification, represents the current research frontier. Commercial applications remain early-stage, but the trajectory is clear, and the addressable market is large.
Diffusion language models: Transformers generate text autoregressively: one token at a time, left to right, each output conditioned on all previous outputs. Diffusion models take a different approach: they start with noise and iteratively refine toward a coherent output, a process that can be parallelized more efficiently for certain tasks. Inception Labs' Mercury demonstrated a diffusion language model that processes text in parallel rather than sequentially, with speed advantages over autoregressive models for latency-sensitive applications. The architecture is earlier-stage than MoE or state-space models but represents a live direction with commercial investment behind it.
World models: Where the four architectures above all predict the next token in a sequence, world models predict the next state of an environment, conditioned on an action. The model takes in observations and produces a plausible next observation given what an agent did. This is the architecture beneath modern self-driving simulation (Wayve's GAIA-1 and GAIA-2), interactive 3D environments (Google DeepMind's Genie 3, Decart's Oasis), and robotics policies trained 'in dreams' before deployment to real hardware (Meta's V-JEPA 2, Comma.ai's openpilot policy). Two architectural families exist inside this category. Generative world models, pursued by Wayve, General Intuition, Runway, and Decart, produce visible playable futures in pixels or 3D scenes. Latent world models, including Yann LeCun's JEPA work at AMI Labs and the philosophical descendants of DeepMind's MuZero, predict in compressed abstract space, throwing away unpredictable visual detail in exchange for efficiency. The category is real, and the capital behind it suggests serious investors believe the path to embodied AI runs through architectures that look very little like transformers.
The infrastructure implication
Each of these alternatives has a different compute profile than the transformer. State-space models prioritize memory bandwidth over floating-point operations. Mixture of Experts requires efficient routing infrastructure and large total parameter capacity. Neurosymbolic systems need tight integration between neural and symbolic compute. Diffusion models benefit from different parallelization patterns than autoregressive generation.
World models have a different profile again. Generative world models are heavy on diffusion and visual decoding, with real-time interactive inference requirements that current inference stacks weren't designed for. Decart, for example, is moving from Nvidia GPUs to Etched's transformer-specific ASICs because of latency demands. Latent world models like JEPA push compute toward representation learning rather than pixel generation. Neither workload looks much like the matrix multiplication patterns the current GPU buildout is optimized for.
This is the infrastructure implication that current capital allocation has not fully absorbed. The GPU clusters being built today are optimized for the matrix multiplication operations that transformer attention requires. They are transformer infrastructure. As alternative architectures move from research into production, the compute platforms serving them will need to adapt, and the adaptation will not be purely software.
The companies positioned for this transition are those building model-agnostic inference infrastructure. Groq, whose custom inference chips were designed around throughput and latency rather than training-scale brute force, can serve multiple model architectures efficiently. Cerebras, with its wafer-scale chip architecture, targets workloads that prioritize memory bandwidth over raw floating-point compute — a profile better suited to several of the emerging architectures. The open-source inference engine vLLM, now serving requests for dozens of model types, represents the software layer of the same flexibility bet.
The training clusters of today are the mainframes of tomorrow. The inference layer is the cloud.
The thesis follows directly: the companies that build model-agnostic inference infrastructure will capture more durable value than those betting a single architectural paradigm will persist. Just as the internet's value accrued to the protocol layer — TCP/IP, HTTP — rather than to any single hardware configuration, AI's enduring value will accrue to the flexible inference layer that can serve any model, any architecture, any workload.
Transformers are the internal combustion engine
The bipolar-to-CMOS transition is instructive precisely because CMOS did not win by being better than bipolar at everything bipolar could do. For years, it wasn't. It won because it was good enough at most things and radically cheaper at scale. That combination of sufficient capability and superior economics made CMOS the foundation of every computing generation that followed, including the GPU architectures that now power the transformer era.
Transformers are the internal combustion engine of AI: transformative, dominant, and not the final form. The alternatives emerging today are not better than transformers at everything transformers can do. At least, not yet. State-space models sacrifice some of transformers' flexibility for long-context efficiency. MoE models require sophisticated routing infrastructure. Neurosymbolic systems cover a narrower task surface. Diffusion models are earlier in their development curve. None is a complete replacement. And some alternatives are competing to be a better transformer; world models are competing to be a different kind of model entirely.
But each addresses a specific limitation that transformers carry as an architectural property, not a product bug. And each is advancing along a cost-and-capability curve that has historically tended to surprise those who assumed the current dominant form would persist. The companies with the deepest transformer expertise — OpenAI, Anthropic, Google — are not standing still; all three have active research into alternative approaches and hybrid architectures. They are not assuming permanence either.
What this means for investors and builders
Four practical conclusions follow from this analysis.
First, evaluate training and inference investments on different timelines. The frontier training workload will remain transformer-centric for several years — the returns on transformer scaling are still positive, and the talent and tooling are concentrated there. But the inference layer, which will serve an architecturally diverse model ecosystem as the field fragments, requires different infrastructure planning. A training cluster optimized for one architecture is capital equipment for a specific workload. A flexible inference platform is a durable business.
Second, the Mixture of Experts transition is already underway and its capital implications are regularly underestimated. MoE's per-query compute reduction does not simply make existing AI cheaper; it changes the economics of which applications become viable. Use cases that were uneconomical at transformer inference costs may cross into viability as MoE deployment scales. That is both an opportunity and a risk for existing AI infrastructure investments premised on current cost structures.
Third, the neurosymbolic direction represents the most underappreciated long-term bet. The domains where verifiable correctness matters — law, medicine, science, finance — are the domains where AI can deliver the most durable economic value and command the highest revenue per interaction. A medical AI that is statistically plausible is a liability. One that can show its reasoning and verify it against clinical evidence is a product. The architectural shift required to build that product is not incremental. It is a different approach to intelligence, and the timeline to commercial viability is measured in years, not decades.
Fourth, the embodied AI category is being built on a different foundation entirely. The capital flowing to world models is not a bet on a faster transformer. It is a bet that robotics, autonomous vehicles, and physical-world automation require action-conditioned models that transformer infrastructure cannot serve well. For capital allocators with exposure to physical-world AI or to the inference layer that will serve it, this is the architectural question that matters most.
The AI infrastructure buildout underway is real and necessary. The question for capital allocators is not whether to invest, it is whether the infrastructure being built today is optimized for the architecture of the next three years or the next ten. History is consistent on this point: the companies that assumed their dominant architecture was permanent did not lead the transition that followed. The ones that built for flexibility captured the value. The winning bet is not the best engine. It is the most flexible chassis.
Sources and data notes
Bipolar-to-CMOS transition: IEEE Solid-State Circuits Society historical records; Caltech and Stanford semiconductor research archives.
Mamba / state-space models: Gu and Dao, 'Mamba: Linear-Time Sequence Modeling with Selective State Spaces,' Carnegie Mellon / Princeton, 2023; Mamba-2 follow-on research, 2024.
Mixture of experts: Google Gemini technical report; Mistral AI Mixtral model card; DeepSeek-V2 and DeepSeek-V3 technical reports, 2024-2025.
Neurosymbolic / AlphaProof: DeepMind, 'AI achieves silver-medal standard solving International Mathematical Olympiad problems,' July 2024.
Diffusion language models: Inception Labs, Mercury technical documentation and benchmarks, 2025.
Inference infrastructure: Groq and Cerebras public technical disclosures; vLLM project documentation (UC Berkeley Sky Computing Lab).
World Models: Ha and Schmidhuber, "World Models," 2018; Wayve GAIA-1 (2023) and GAIA-2 (2025) technical reports; Meta V-JEPA 2 paper, 2025; Google DeepMind Genie 3 documentation, 2025; LeCun, "A Path Towards Autonomous Machine Intelligence," 2022.

Download the full report
The economics, architecture, and future of AI, and what must change for ubiquitous, on-demand intelligence to become a sustainable, long-term reality.




